
There is a substantial amount of data generated on the internet every second – posts, comments, photos, and videos. These different data types mean that there is a lot of ground to cover, so let’s focus on one – text.
All social conversations are based on written words – tweets, Facebook posts, comments, online reviews, and so on. Being a social media marketer, a Facebook group/profile moderator, or trying to promote your business on social media requires you to know how your audience reacts to the content you are uploading. One way is to read it all, mark hateful comments, divide them into similar topic groups, calculate statistics and… lose a big chunk of your time just to see that there are thousands of new comments to add to your calculations. Fortunately, there is another solution to this problem – machine learning. From this text you will learn:
- Why do you need specialised tools for social media analyses?
- What can you get from topic modeling and how it is done?
- How to automatically look for hate speech in comments?
Why are social media texts unique?
Before jumping to the analyses, it is really important to understand why social media texts are so unique:
- Posts and comments are short. They mostly contain one simple sentence or even single word or expression. This gives us a limited amount of information to obtain just from one post.


- Emojis and smiley faces – used almost exclusively on social media. They give additional details about the author’s emotions and context.


- Slang phrases which make posts resemble spoken language rather than written. It makes statements appear more casual.

These features make social media a whole different source of information and demand special attention while running an analysis using machine learning. In contrast, most open-source machine learning solutions are based on long, formal text, like Wikipedia articles and other website posts. As a result, these models perform badly on social media data, because they don’t understand additional forms of expression included. This problem is called domain shift and is a typical NLP problem. Different data also require customised data preparation methods called preprocessing. The step consists of cleaning text from invaluable tokens like URLs or mentions and conversion to machine readable format (more about how we do it in Sotrender). This is why it is crucial to use tools created especially for your data source to get the best results.
Topic Modeling for social media
Machine learning for text analysis (Natural Language Processing) is a vast field with lots of different model types that can gain insight into your data. One of the areas that can answer the question “what are the topics of given pieces of texts?” is topic modeling. These models help with understanding what people are talking about in general. It does not require any specially prepared data set with predefined topics. It can find topics which are patterns hidden within the data on its own without supervision and help – which makes it an unsupervised machine learning method. This means that it is easy to build a model for each individual problem.
There are lots of different algorithms that can be used for this task, but the most common and widely used is LDA (Latent Dirichlet Allocation). It’s based on word frequencies and topics distribution in texts. To put it simply, this method counts words in a given data set and groups them based on their co-occurrence into topics. Then the percentage distribution of topics in each document is calculated. As a result this method assumes that each text is a mixture of topics which works great with long documents where every paragraph relates to a different matter.
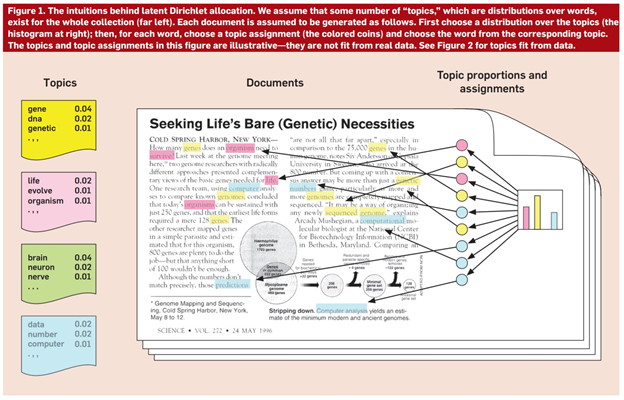
Figure 1. LDA algorithm (Credit: Columbia University)
That’s why social media texts need a different procedure. One of the new algorithms is GSDMM (Gibbs sampling algorithm for a Dirichlet Mixture Model). What makes this one so different?:
- It is fast,
- designed for short texts,
- easily explained with an analogy of a teacher (algorithm) that wants to divide students (texts) into groups (topics) of similar interests.
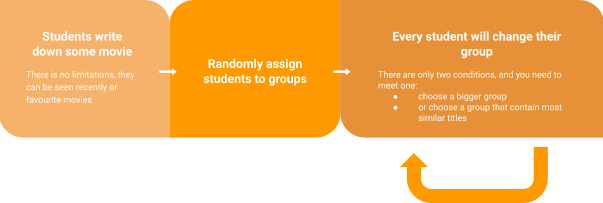
Figure 2. Group assignment algorithm
Students are told to write down some movie titles they liked within 2 minutes. Most students are able to list 3-5 movies with this time frame (it corresponds to a limited number of words for social media texts). Then they are randomly assigned to a group. The last step is for every student to pick a different table with two rules in mind:
- pick a group with more students – favours bigger groups
- or a group with the most similar movie titles – makes groups more cohesive.
This last step is repeated multiple times. First rule that favours bigger groups is crucial to ensure that groups are not excessively fragmented. Due to the limited number of movie titles (words) for each student (text), each group (topic) is bound to have members with different movies in their lists but from the same genre.
As A result of the GSDMM algorithm you obtain an assignment of each text to one topic, as well as a list of the most important words for every topic.

Figure 3. Documents assignment to topics and getting topic words
The tricky part is to decide upon number of topic (problem of every unsupervised method) but when you finally do this you can gain quite of a lot of insights from the data:
- Distribution of topics in your data
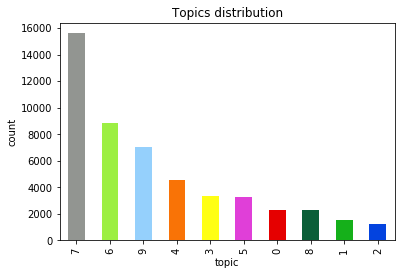
Figure 4. Topic distribution in data
- Word Clouds – allows us to comprehend the topic and name it. It is a quick and easy solution that can replace reading the whole set of text and spare you hours of tedious work of dividing it into sets.

Figure 5. You can see in the picture above three examples of word clouds. Looking from left to right, the first one contains words: president, government, disease, covid – we can assume the main theme is politics. There are also less prominent words like cough, sick and health so it’s a topic about government actions regarding health issues.
- Time series analysis of topics – As we can see in the plot below some topics can gain more attention like number 7 and some of them fade away like number 4. Trying to grasp the idea of what is popular or can be popular in the future is a good thing to look back and see how topics were changing in the past.

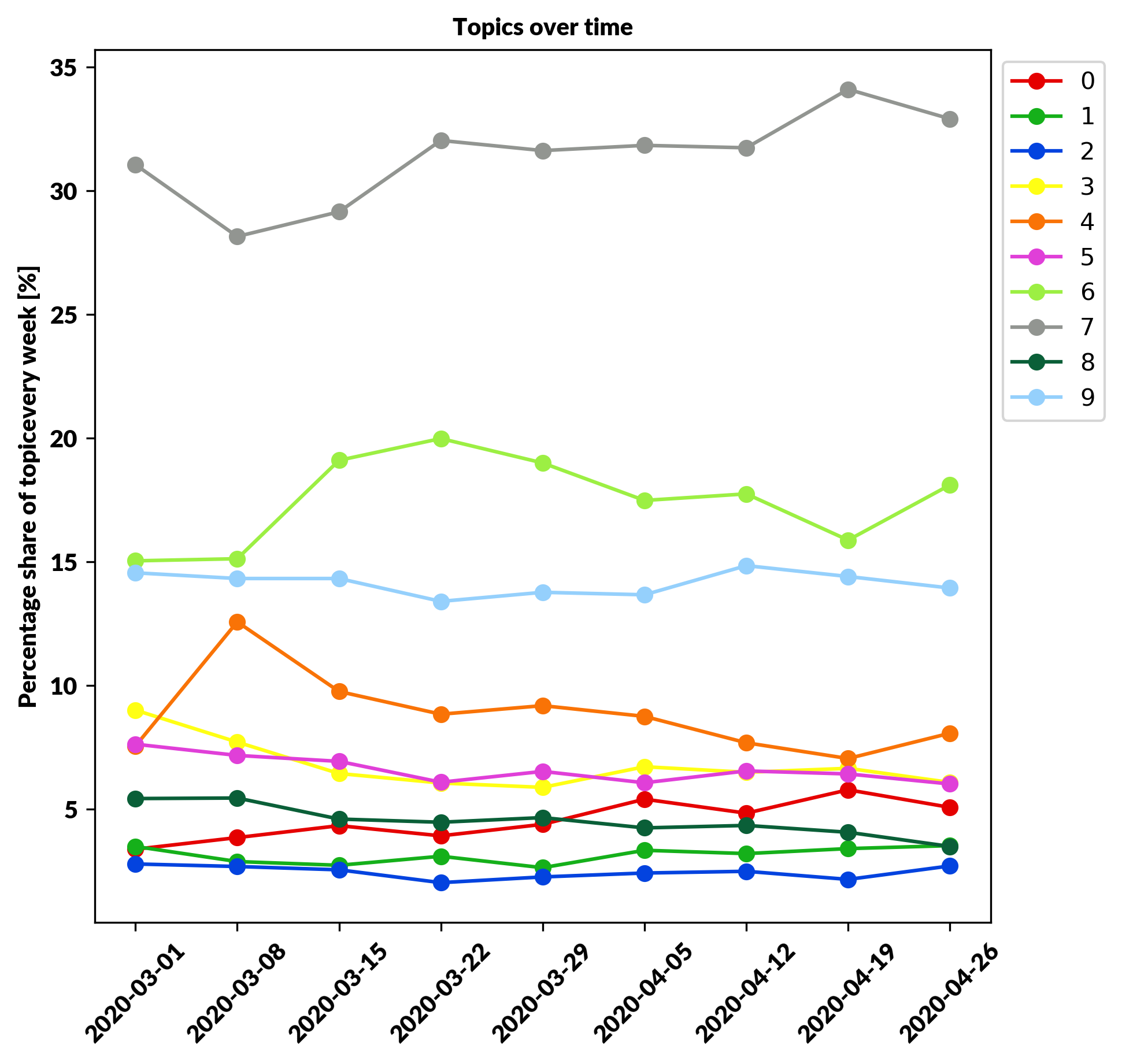
Figure 6. Distribution of topics over time.
Use case
In one of our recent projects for Collegium Civitas we analyzed 50 000 social media posts and comments and performed topic analysis on them. It allowed our client to answer questions like:
1) What was discussed in the time span of 2 months in social media?
In the dataset we were able to distinguish 10 different topics, revolving around COVID-19. Discussions covered statistics and COVID-19 etiology, everyday life, government response to pandemic, consequences of limitations in traveling, trade market and supplies, everyday life, health care during pandemic, church and politics, common knowledge and conspiracy theories of COVID-19, politics and economy, spam messages and ads.
2) How were the discussions influenced by the pandemic situation?
During the pandemic burst the biggest theme was the origin and statistics of COVID-19. People talked about how the situation is changing and exchanged information about ways of disease spreading . To read more visit Collegium Civitas’s site (there is only a Polish version).
Hate speech recognition
Another question that can be answered with machine learning is “what kind of emotion do people express in their comments or posts?” or “is my content generating hateful comments?”. There are only a few solutions for these tasks in the Polish language. That is why we build models based on social media text for Sentiment and Hate Speech recognition at Sotrender. Our solutions were built in two steps.
The first step is to convert text and emojis into numerical vector representation (embeddings) to be used later in neural networks. The main goal of this step is to achieve some kind of language model (LM) that has the knowledge of a human language so that vectors representing similar words are close to each other (for example: queen and king or paragraph and article) which implies that these words have similar meaning (semantic similarity). The property is shown on the graph below.
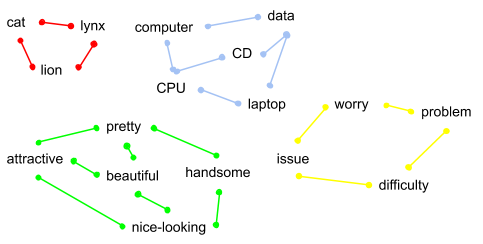
Figure 7. The intuition behind word similarity
Training this model is similar to teaching a child how to speak by talking to them. Children by listening to their parents talk are able to grasp the meaning of words and the more they hear the more they understand.
According to this analogy, we have to use a huge set of social media text to train our model to understand its language. That is why we used a set of 100 millions posts and comments to train our model so it can properly assign vectors to words as well as to emojis. Tokens vectorised with an embeddings model provide the input to the neural network.
The second step is designing neural networks for a specific task – Hate speech recognition. The most important thing is the data set – the model needs examples of hate speech and non-hateful texts to learn how to tell them apart. In order to get best results you need to experiment with different architectures and model’s hyperparameters.
As a result of the hate speech recognition model, we get another grouping of our data set. Now we can see how our audience reacts, how many hateful comments or posts it’s creating. What’s more, by combining it again with the time of publication of each comment, we can see if there was a specific time period when the most hateful comments were generated like shown in a histogram below.
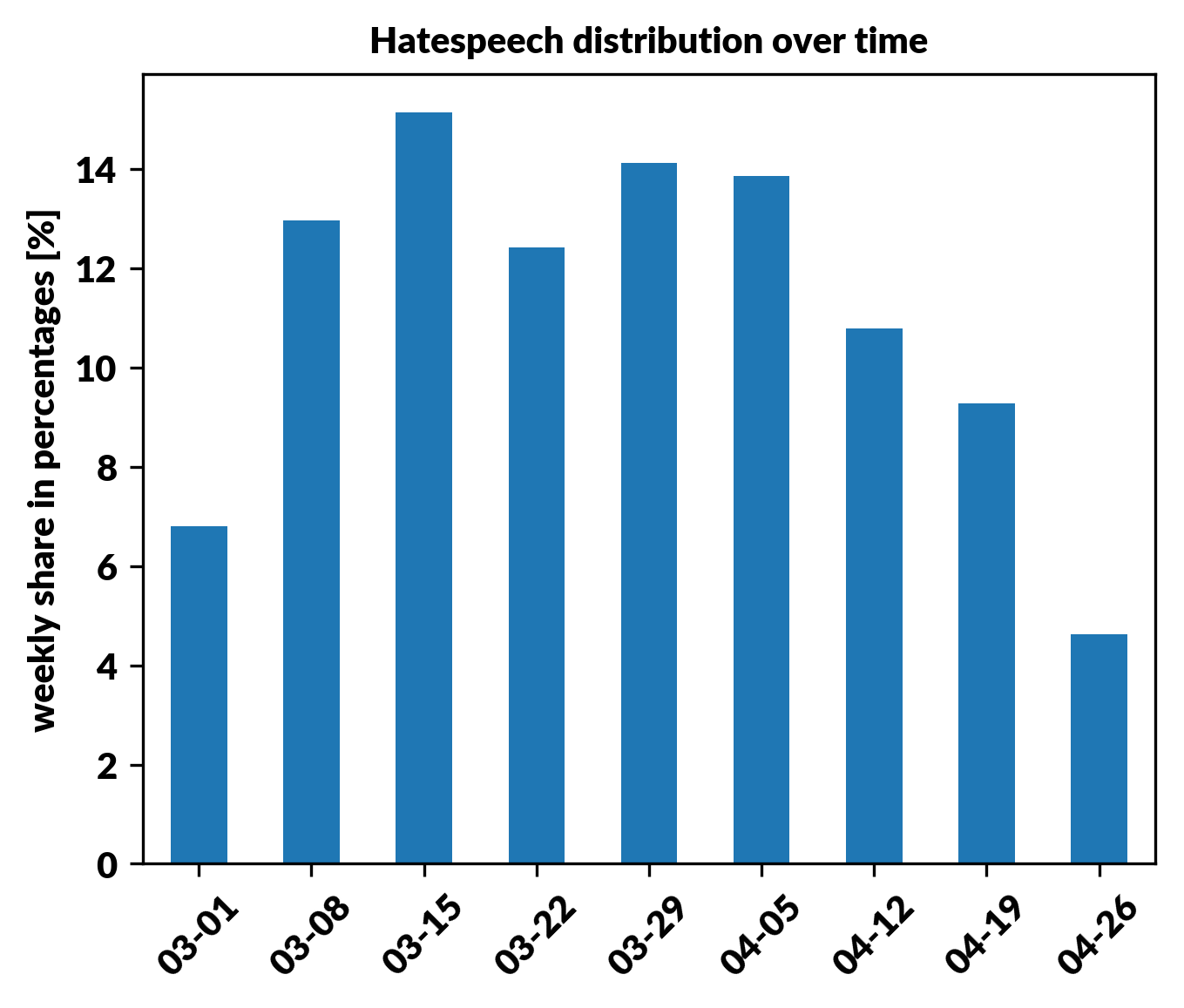
Figure 8. Hate Speech distribution over time
Combining this distribution with recent posts or events can give you insight into the type of content that provokes people. Also changes of hate speech contribution in time can be related with changes in topic distribution. Combining all the information from analysis can provide an in-depth image of the dataset.
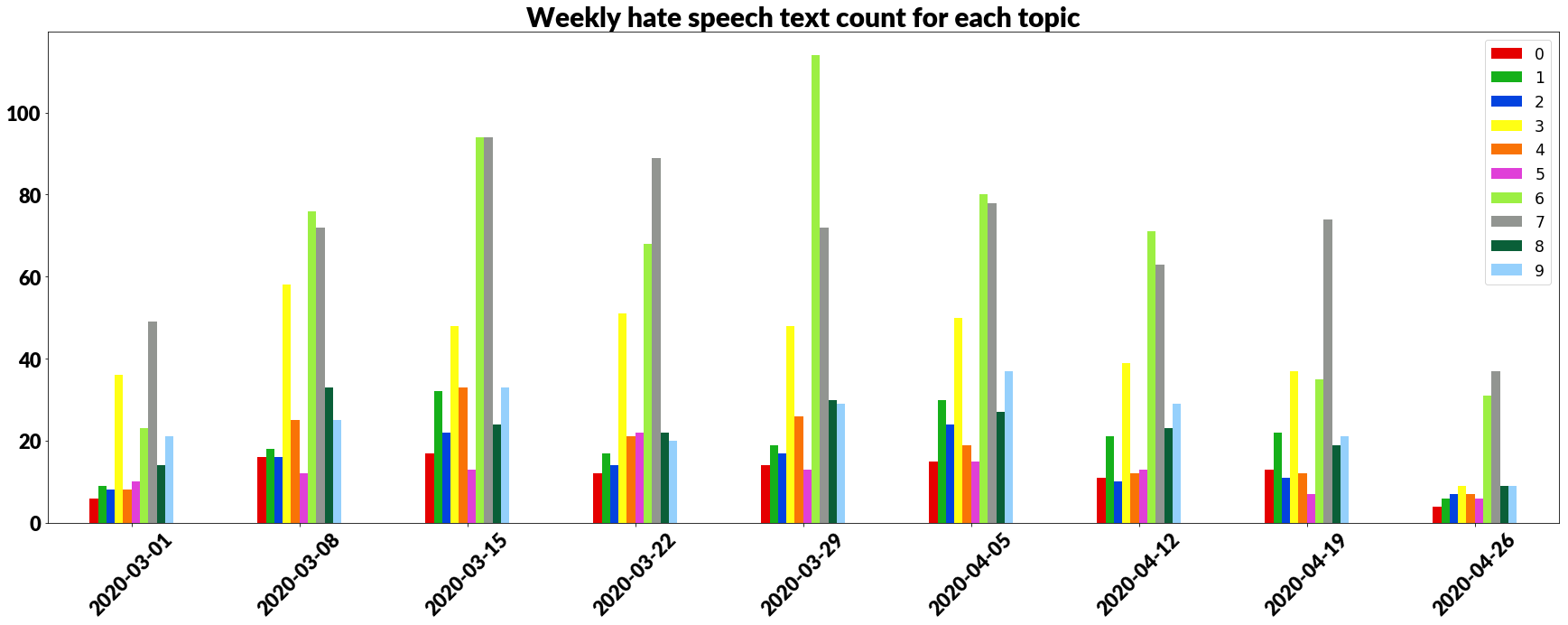
Figure 9. Weekly text count with hate speech
As the histogram above shows most hate is connected to topic 3, 6 and 7. Knowing what makes people angry gives the opportunity to avoid sensitive topics in the future.
Same goes for sentiment analysis. We can produce similar visualizations for positive, negative or neutral comments and see their distribution in time or topics. If you would like to read the whole report build based on our analysis of there 8 weeks of data you can find it here (only Polish version).
Conclusion
We have models for hate speech and sentiment recognition that are constantly improved and updated for social media texts here at Sotrender. What’s more, we have experience in building topic modeling models for individual cases. As you can see there’s a lot of benefits coming from this type of analysis:
- Getting to know your audience
- Having in depth look into topics of comments
- Discovering trending themes
- Finding source of hatred or negativity in our content
To name just a few!
If you’re interested in learning more about how we can use our machine learning models for your brand’s social media profiles, feel free to contact our Sales team for more information. 😉


