
Despite the fact that we are not in the kind of future that the Jetsons anticipated, the present and future of Artificial Intelligence (AI) and Machine Learning (ML) are impressive. AI and ML subdivisions have been developing at such a rapid pace that it might be difficult to keep up. You might have heard about Natural Language Processing, but perhaps you aren’t convinced of its potential. Can you even use AI in the realm of social media marketing, and should you?
What NLP is for
By utilizing Natural Language Processing (NLP), a computer can start to understand how people communicate, in vivo or over text. By the end of it, the computer will have understood and deciphered units of text or speech so it can be analyzed or replicated across settings. Instead of having a marketer code every word or phrase and segmenting them into categories in a repetitive, potentially error prone way, you can use AI to do this for you. What’s more, if you have more than one person coding the same data, they may choose to code variables differently. An AI will implement the rules you have assigned to it, and it will adapt based on the data you feed it.
NLP can help us analyze interactions between people online. Let’s take a look at some of the information it can gather:
- what people are writing about without having to read the whole text.
- what conversations people are engaged in are about and keep track of the changes in the conversation.
- track reactions and feelings about posts, brands, products, campaigns, and events.
Why does it matter?
If you work solely with quantitative data, you might not know how qualitative data such as text or string can be quantified, analyzed, and reproduced. To address this challenge, employing descriptive studies for gathering data that involves the simultaneous use of quantitative and qualitative research approaches is highly recommended. This approach allows for a comprehensive understanding of the group or object under study, providing a more holistic and insightful picture of the subject matter.
Typically, if a brand wants to know how their product or services are being received, their marketing department sends out a survey to gauge how satisfied their customers are. But what if very few people actually answer these surveys? What if your questions don’t ask enough about the nuances of your customer’s opinions?
With NLP, you won’t be limited to providing a survey with closed questions that can only be coded as numbers. NLP creates metadata like text descriptors, tags, and categories that can be assigned to phrases or words. It can come in handy when you need to make strategic decisions about content creation and how to improve the quality of customer support or products. If the same words appear regularly, it can “take the hint”.

How do ML and AI process natural language?
Artificial Intelligence or AI for short, is typically used to refer to machines and computers mimicking human cognition such as learning, planning, and reasoning. Machine Learning (ML) on the other hand, depends on patterns to make predictions and study algorithms and statistical models. There are different methods for using both, and Sotrender utilizes them both to some extent. Sotrender is currently working with sentiment analysis, cyberbullying, topic models, and keyphrase extraction.
Let’s take a look at the third point again (tracking reactions and feelings about posts). Sentiment analysis can recognize and quantify emotional states and feelings directed at something. It can indicate the valence (positivity or negativity) of a unit of text. A customer leaving a comment using words such as “happy” or “satisfied” will be coded as an overall positive sentiment. Similarly, it can also identify hate speech and the different forms it can appear in, regardless the use of epithets. Essentially, it can pick up on the subtleties of aggression by utilizing techniques such as deep learning.
English Examples:
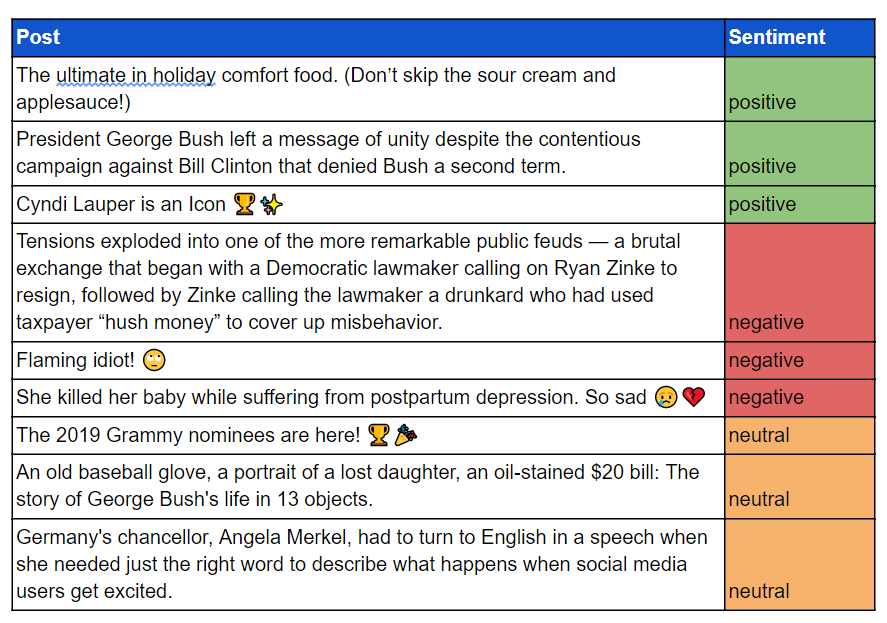
Polish Examples:

As mentioned previously, NLP can tell you what the text is about. This is achieved via topic modelling and keyword extraction. Topics modelling is a way of organizing text into groups or clusters. The clusters are defined by words that frequently occur together in documents. Thus, topics are described by the list of such words. Additionally, words that were chosen by the algorithm are the most representative for a particular cluster. In other words, it is relatively easy for a human to distinguish one cluster from another and label them based on these words. Keyword or keyphrase extraction is similar to topic modelling as the method also extracts the most informative or important words or phrases. However, this applies only to the current document, and not the whole collection of documents. Instead of grouping documents, we are focused on getting key information from a text without having to read it. In short, it resembles assigning tags to text.

Keywords:
turing award, subfield, deep neural networks, last email, technology, computer science, geoffrey hinton, huge breakthroughs, speech recognition, artificial intelligence
Our plan for the future is to conduct text categorization based on various ontologies, content scoring, sentiment monitoring in conversations or moderations, automatic text generation, and a moderation chatbot.
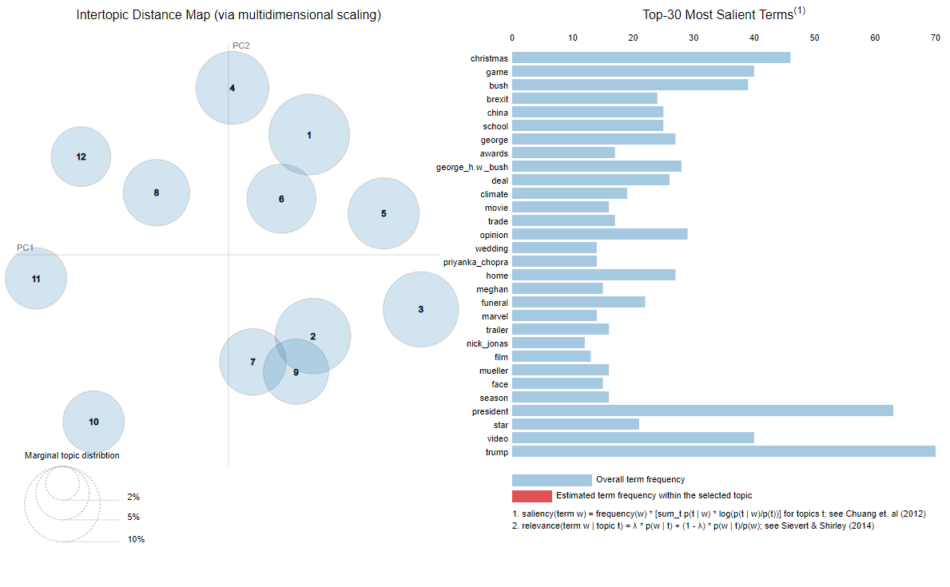
Why is NLP difficult (even for people)?
NLP comes with its own challenges and obstacles to get around. Even those who have experience using ML and AI will tell you that. The language used and analyzed should be unambiguous, for both people and ML models. This isn’t always the case with posts on social media. So what is it that makes natural language processing so difficult? Grammar and rules of language use become murkier as languages change over time. These, and other aspects, should be considered when using NLP and ML. This brings us to context, one of the important aspects because of its role in learning meaning and understanding text data.
Ambiguous language can be problematic when you want to extract meaning from phrases. Syntactic ambiguity in English is an obstacle for sure, as certain sentences can be interpreted in more than one way if there is no additional context. Changing the syntax of the sentence could give it a whole new meaning. Let’s imagine somebody wrote a tweet along these lines:
i ran into my favorite pole!
Humans would understand what “pole” is referring to because of a representativeness heuristic, so they can estimate the probability of using “pole” as nationality is more likely than a stick. They also understand the colloquialism of “running into” someone. Without additional context, machines wouldn’t be able to distinguish between the author running into a physical object and if they saw their favorite Polish person. What’s more, we can’t tell what part of the phrase is emphasized. Even a phrase such as “I love you” is ambiguous without additional context such as word stress, target, and interlocutor’s intention and style. However, “/s” has recently been used to denote sarcasm in text posts, which could make ML easier if it is a mainstream practice.

Although the unofficial lingua franca of the internet is English, other languages appear either by themselves or mixed in with another language. Not to mention all of the dialects, regional slang, and career specific jargon that has different meanings to its colloquial use. Consider a word such as “extra”. Although it usually means “surplus” or “additionally”, it’s commonly used in social media to denote something or somebody being “too much” or going overboard. In certain Slavic languages, words like “extra” and “mega” can be used to frame the topic in a positive light. On top of that, there are differences in the ways that languages are combined in everyday language, which makes language identification difficult at the beginning. Polish posts have the tendency to mix English and Polish in one go, whereas comments made primarily in English do not.
Other patterns have emerged, with varied emoji use. Emojis can be used in different ways, especially because of the discrepancies that exist between Android, iPhone, and Windows phone users. Sometimes emojis are related to a specific context that may not be revealed in the rest of the comments. If you spent enough time on Instagram the last few years, you might have noticed people leaving single emoji comments that could reference specific events.
The lack of training datasets from social media can make it difficult to use Machine Learning for Natural Language Processing. Open-source datasets can be used to benchmark your ideas with other state-of-the-art solutions. Unfortunately, there are almost no open-source NLP datasets in Polish. By having open-source datasets, you can start with building general model and then fine-tune it to your data. Because such data is scarce, you have to create your own dataset with annotations at the very beginning. This is just something to consider when building your model – how can you implement ML when your audience is multilingual and there aren’t diverse datasets readily available?
The data is extremely diverse across platforms, since every platform has a different use and medium for posts. Twitter has a limit of 280 characters per tweet, which means reducing letters or coming up with shortcuts such as “LOL” or “SMH”, whereas Facebook allows for longer text posts where this isn’t necessary.
Twitter is primarily a text platform, though users do share videos and images. Instagram is almost completely visual, though the description and comments vary. Some platforms will also feature memes or jokes more often than others, while others are mostly used for personal updates.
It’s a lot to consider, but these are very real problems without simple solutions.
Is it rocket science?
In a way it is. We need to stay up to date with the newest approaches to Natural Language Processing and at the same time come up with ways to adopt them on social media. The datasets you will need require creativity, whereas the models should be generalizable to new or future data. If the model works only for a few users, but cannot be generalized to more posts and users, the conclusions aren’t valid. As statisticians say, garbage in, garbage out. That’s why the quality of your dataset matters, and if you select text that is not representative of your audience, you may come up with a social media strategy or set of responses that is not congruent with what your audience is telling you.
Since the datasets are not immediately provided to us, we have to arrange our work in iterations (iterations refer to the number of times parameters of an algorithm are updated). We experiment with different methods on the available annotated data, pick the best performing one, and build the first model. Next, we check how much the model has already learnt and how different our data are. Simultaneously, we create annotation pipelines and research faster and more flexible methods for data labelling. This way models can be fed with new data which improves their understanding of social media language. The first model we test is far from perfect, but we benchmark it against newer ones where we make controlled adjustments. Eventually when we want to adjust the model to social media, we have to find what parts of the models have the highest potential to give us better quality results.
Conclusions
Artificial Intelligence, and Machine Learning in particular, can be used to analyze the way that people use language to indicate their thoughts, feelings, and to describe actions. Each of your questions may be answered with a different technique, but the solutions and methods are far from perfect.
We highly recommend you keep the challenges of NLP in mind and that you become familiar with the different techniques available. Quality data and good practices take time to acquire. It is definitely worth it if you want a general understanding of what your audience wants and what are the themes that keep coming back to their conversations about your brand.


